实验说明
在 cache lab 实验中,包含两个部分:
- 第一部分要求我们写一个 C program 来模拟 cache memory。
- 第二部分要求我们通过减少 cache miss 来优化一个矩阵转置函数。
对应的文件分别为csim.c, trans.c
可通过make和make clean来编译和删除编译文件。
PartA Writing a Cache Simulator
准备工作
我们利用valgrind生成的 trace files 作为我们 cache simulator 的 input。
格式为[space]operation address, size:
I 0400d7d4,8
M 0421c7f0,4
L 04f6b868,8
S 7ff0005c8,8
- I 加载指令
- L 加载数据
- S 存储数据
- M 内存数据修改(先加载数据,再存储数据)
I 前面不跟空格,L/S/M 前面需要加一个空格。
csim-ref是一个参考的 cache simulator 实现。使用LRU替换算法。
用法: Usage: ./csim-ref [-hv] -s <s> -E <E> -b <b> -t <tracefile>
-h: Optional help flag that prints usage info-v: Optional verbose flag that displays trace info-s <s>: Number of set index bits (S = 2s is the number of sets)-E <E>: Associativity (number of lines per set)-b <b>: Number of block bits (B = 2b is the block size)-t <tracefile>: Name of the valgrind trace to replay
e.g.
./csim-ref -s 4 -E 1 -b 4 -t traces/yi.trace
hits:4 misses:5 evictions:3
./csim-ref -v -s 4 -E 1 -b 4 -t traces/yi.trace
L 10,1 miss
M 20,1 miss hit
L 22,1 hit
S 18,1 hit
L 110,1 miss eviction
L 210,1 miss eviction
M 12,1 miss eviction hit
hits:4 misses:5 evictions:3
解答
先放上最终的csim.c
解析命令行
首先要从命令./csim -v -s 4 -E 1 -b 4 -t traces/yi.trace获取 cache 的参数,包括s,E,b和 trace 的文件。
这里需要用到一个 C 库函数getopt来处理命令行参数。
我们在extract_parameters函数中处理,把解析出来的参数放进结构体cache_para中,sets,lines,bits分别来自于-s, -E, -b。verbose_flag用来打印详细信息,由-v决定是否置起,output_file保存 trace 文件名字符串。
struct cache_para
{
int sets; // s
int lines; // E
int bits; // b
char *output_file;
bool verbose_flag;
} cache;
分配 cache 空间
我们用一个二维数组来模拟 cache。参考书中的 cache 结构:
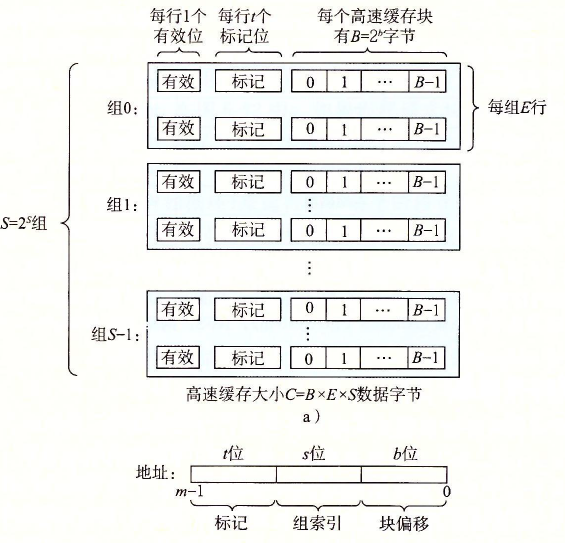
struct cache_block用来抽象每一行 cache line。其中tag用来保存标记,valid保存有效位,time用来记录该 block 在 cache 中停留的时间,用于后面的 LRU 替换算法。
这边没有记录每一条 cache line 中的数据,因为该实验中只需要记录命中/未命中/替换,而 cache 中内容的替换是自动进行的,不需要我们操作。
struct cache_simulator用来抽象整个 cache 结构,是一个二级数组,第一级保存了第 x 组的起始地址,第二级则是每 x 组中的第 x 行。
struct cache_block
{
unsigned long tag;
int time;
bool valid;
};
struct cache_simulator
{
struct cache_block **blocks;
} cache_sim;
在allocate_cache函数中通过 malloc 函数分配空间,这边要注意二级数组的分配方法。
先分配二级数组的大小,是组的数量*保存每个组起始地址的指针大小。
再分配每个组的大小,是每组行的数量*每个 cache block 的大小。
static void allocate_cache(void)
{
int set_size = 2 << cache.sets; // S=2^s
cache_sim.blocks =
(struct cache_block **)malloc(sizeof(struct cache_block *) * set_size);
for (int i = 0; i < set_size; i++)
{
cache_sim.blocks[i] =
(struct cache_block *)malloc(sizeof(struct cache_block) * cache.lines);
memset(cache_sim.blocks[i], 0x0, cache.lines * sizeof(struct cache_block));
}
}
模拟 cache 行为
在decode函数中,利用fgets从 trace 文件中每次读取一行保存进字符串。
再利用sscanf从字符串中提取出 trace 文件的每一行中指令的 type,加载/存储的地址和大小。
接着从地址中我们可以解析出组的索引和该地址的标记。
static int cache_process(char *line)
{
sscanf(line, " %c %lx,%d\n", &type, &address, &size);
s_idx = (address >> cache.bits) & ((1 << cache.sets) - 1);
tag = address >> (cache.bits + cache.sets);
}
PartB Optimizing Matrix Transpose
准备工作
要求:
- 每个 transpose function 最多使用 12 个 int 类型的局部变量。
- 不允许使用任何 long 类型的变量或使用任何位技巧将多个值存储到单个变量中来规避上一条规则。
- 不可以使用递归。
- 可以用在 transpose function 中使用子函数,但总的局部变量仍然不能超过 12 个。
- 不能修改数组 A,可以修改数组 B。
- 不可以额外定义数组或使用 malloc。
题目设定 cache 的参数为:\(s=5,E=1,b=5\)。
会根据 3 种情况来评估最后的代码实现,32*32 表示矩阵大小,m 表示 cache miss:
- 32 × 32: 8 points if m < 300, 0 points if m > 600
- 64 × 64: 8 points if m < 1, 300, 0 points if m > 2, 000
- 61 × 67: 10 points if m < 2, 000, 0 points if m > 3, 000
评估只针对这三种情况正确,可以针对这三种情况进行专门优化。函数可以明确检查输入大小并针对每种情况实现单独的优化代码。
trans.c中trans是参考的实现,我们要实现transpose_submit函数。
可以利用test-trans来检测实现是否正确:
linux> ./test-trans -M 32 -N 32
linux> ./test-trans -M 64 -N 64
linux> ./test-trans -M 61 -N 67
成功运行后还会生成trace.f0,为我们实现的函数访问内存的指令序列。
可以执行 partA 中的 cache 模拟器./csim-ref -s 5 -E 1 -b 5 -t trace.f0 来查看 hit/miss/expire 的情况。