Reserved-memory
参考:http://www.wowotech.net/memory_management/cma.html
https://xilinx-wiki.atlassian.net/wiki/spaces/A/pages/18841683/Linux+Reserved+Memory?view=blog
/Documentation/devicetree/bindings/reserved-memory/reserved-memory.txt
定义了 no-map 属性的,不会自动映射到虚拟地址,需要自行在 driver 中映射。
// dts
reserved: buffer@0x38000000 {
no-map;
reg = <0x38000000 0x08000000>;
};
/* Get reserved memory region from Device-tree */
np = of_parse_phandle(dev->of_node, "memory-region", 0);
rc = of_address_to_resource(np, 0, &r);
lp->paddr = r.start;
lp->vaddr = memremap(r.start, resource_size(&r), MEMREMAP_WB);
定义"shared-dma-pool" 就可以创建 DMA memory pool,使用 DMA engine API 了。of_reserved_mem_device_init 中会帮我们创建映射。(DMA 在 of_reserved_mem_device_init 阶段会进行 memremap 同上,这个 remap 不是直接映射的方式)。
// dts
reserved: buffer@0 {
compatible = "shared-dma-pool";
no-map;
reg = <0x0 0x70000000 0x0 0x10000000>;
};
/* Initialize reserved memory resources */
rc = of_reserved_mem_device_init(dev);
/* Allocate memory */
dma_set_coherent_mask(dev, 0xFFFFFFFF);
lp->vaddr = dma_alloc_coherent(dev, ALLOC_SIZE, &lp->paddr, GFP_KERNEL);
log:
[ 0.000000] Reserved memory: created DMA memory pool at 0x0000000070000000, size 256 MiB
[ 0.000000] Reserved memory: initialized node buffer@0, compatible id shared-dma-pool
加上 resuable 属性,变成 CMA pool。(CMA 在 dma_alloc_coherent 时会通过__va 宏返回直接映射的虚拟地址)
reserved: buffer@0 {
compatible = "shared-dma-pool";
reusable;
reg = <0x0 0x70000000 0x0 0x10000000>;
};
log:
[ 0.000000] Reserved memory: created CMA memory pool at 0x0000000070000000, size 256 MiB
[ 0.000000] Reserved memory: initialized node buffer@0, compatible id shared-dma-pool
DMA pool 是 driver 独有的,CMA pool 在 driver 不使用的时候会被共享。
Dynamic DMA mapping Guide
https://docs.kernel.org/core-api/dma-api-howto.html
https://zhuanlan.zhihu.com/p/109919756
CPU and DMA addresses
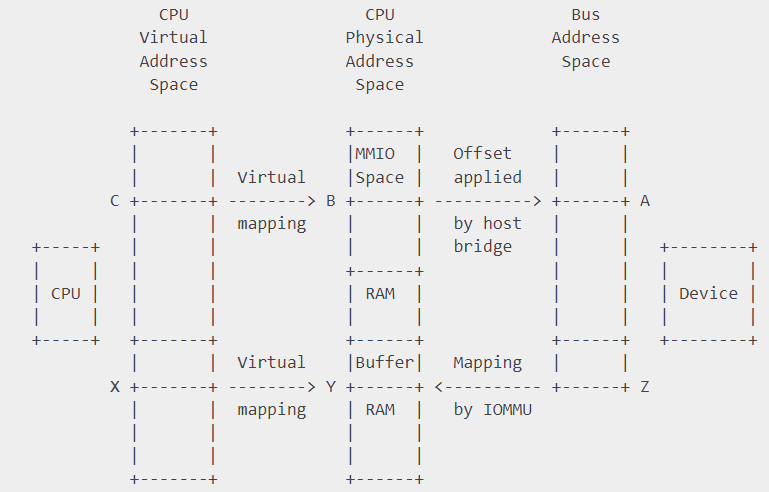
有 IOMMU 的设备,设备 device 访问的地址是 bus address(等同于 dma address),IOMMU 负责 CPU physical address 和 bus address 的映射。
嵌入式设备一般没有 IOMMU,此时 bus address=CPU pyhsical address。设备直接访问 cpu 的物理地址。
What memory is DMA’able?
__get_free_page*(), kmalloc(), kmem_cache_alloc()这些分配连续空间地址的都可以 dma mapping。
vmalloc(), kmap()不行。
DMA addressing capabilities
设置设备通过 DMA 能驱动多少位地址,寻址能力。
同时设置 streaming 和 coherent mapping:
int dma_set_mask_and_coherent(struct device *dev, u64 mask)
只设置 streaming mapping:
int dma_set_mask(struct device *dev, u64 mask);
只设置 coherent mapping:
int dma_set_coherent_mask(struct device *dev, u64 mask);
Types of DMA mappings
- 一致性 DMA 映射(consistent DMA mappings)。driver 初始化时 map,shutdown 时 unmap。
- 不需要考虑 cache 的影响,也就是说不需要软件进行 cache 操作,CPU 和 DMA controller 都可以看到对方对 DMA buffer 的更新。CPU 对 memory 的修改 device 可以立即感知到,反之亦然。
- 一致性的 DMA 映射并不意味着不需要 memory barrier 这样的工具来保证 memory order。
- 在有些平台上,修改了 DMA Consistent buffer 后,你的驱动可能需要 flush write buffer,以便让 device 侧感知到 memory 的变化。
- 流式 DMA 映射(Streaming DMA mappings)。一次性的,需要进行 DMA 传输的时候 map,DMA 传输完成,就 ummap。
spi-dw-rts.c中 ssi 的传输就是流式 dma 映射。
一致性 DMA 映射
dma_addr_t dma_handle;
//cpu_addr:虚拟地址,dma_handle:总线地址,没有IOMMU相当于物理地址
cpu_addr = dma_alloc_coherent(dev, size, &dma_handle, gfp);
You may however need to make sure to flush the processor’s write buffers before telling devices to read that memory.见下方 sync 的 API。
如果 driver 需要许多小的 buffer,可以使用
struct dma_pool *pool;
pool = dma_pool_create(name, dev, size, align, boundary);
cpu_addr = dma_pool_alloc(pool, flags, &dma_handle);
流式 DMA 映射
流式 DMA 映射需要设置 DMA direction。
DMA_BIDIRECTIONAL
DMA_TO_DEVICE
DMA_FROM_DEVICE
DMA_NONE
接口一dma_map_single
struct device *dev = &my_dev->dev;
dma_addr_t dma_handle;
void *addr = buffer->ptr;
size_t size = buffer->len;
dma_handle = dma_map_single(dev, addr, size, direction);
if (dma_mapping_error(dev, dma_handle)) {
/*
* reduce current DMA mapping usage,
* delay and try again later or
* reset driver.
*/
goto map_error_handling;
}
接口二dma_map_page
因为 dma_map_single 函数在进行 DMA mapping 的时候使用的是 CPU 指针(虚拟地址),导致该函数有一个弊端:不能使用 HIGHMEM memory 进行 mapping。因为 HIGHMEM memory 没有进行线性映射,所以没有虚拟地址。
接口三dma_map_sg
用于 scatterlist 情况,映射的对象是分散的若干段 DMA buffer。具体不分析了。
Sync
如果你需要多次访问同一个 streaming DMA buffer,并且在 DMA 传输之间读写 DMA Buffer 上的数据,这时候你需要小心进行 DMA buffer 的 sync 操作,以便 CPU 和设备(DMA controller)可以看到最新的、正确的数据。
dma_sync_single_for_cpu(dev, dma_handle, size, direction)
如果,CPU 操作了 DMA buffer 的数据,然后你又想把控制权交给设备上的 DMA 控制器,让 DMA controller 访问 DMA buffer,这时候,在真正让 HW(指 DMA 控制器)去访问 DMA buffer 之前,需要:
dma_sync_single_for_device(dev, dma_handle, size, direction)
Other
https://blog.csdn.net/wangyunqian6/article/details/6670110
DMA 是直接操作总线地址的,这里先当作物理地址来看待吧。如果 cache 缓存的内存区域不包括 DMA 分配到的区域,那么就没有一致性的问题。但是如果 cache 缓存包括了 DMA 目的地址的话,会出现什么什么问题呢?
问题出在,经过 DMA 操作,cache 缓存对应的内存数据已经被修改了,而 CPU 本身不知道(DMA 传输是不通过 CPU 的),它仍然认为 cache 中的数据就是内存中的数据,以后访问 Cache 映射的内存时,它仍然使用旧的 Cache 数据。这样就发生 Cache 与内存的数据“不一致性”错误。
顺便提一下,总线地址是从设备角度上看到的内存,物理地址是 CPU 的角度看到的未经过转换的内存(经过转换的是虚拟地址)
由上面可以看出,DMA 如果使用 cache,那么一定要考虑 cache 的一致性。解决 DMA 导致的一致性的方法最简单的就是禁止 DMA 目标地址范围内的 cache 功能。但是这样就会牺牲性能。
因此在 DMA 是否使用 cache 的问题上,可以根据 DMA 缓冲区期望保留的的时间长短来决策。DAM 的映射就分为:一致性 DMA 映射和流式 DMA 映射。
因为 LCD 随时都在使用,因此在 Frame buffer 驱动中,使用一致性 DMA 映射上面的代码中用到 dma_alloc_wc(non-cache, buffered)函数,另外还有一个一致性 DMA 映射函数dma_alloc_coherent(non-cache,non-buffer)
static inline void *dma_alloc_coherent(struct device *dev, size_t size,
dma_addr_t *dma_handle, gfp_t gfp)
{
return dma_alloc_attrs(dev, size, dma_handle, gfp,
(gfp & __GFP_NOWARN) ? DMA_ATTR_NO_WARN : 0);
}
static inline void *dma_alloc_wc(struct device *dev, size_t size,
dma_addr_t *dma_addr, gfp_t gfp)
{
unsigned long attrs = DMA_ATTR_WRITE_COMBINE;
if (gfp & __GFP_NOWARN)
attrs |= DMA_ATTR_NO_WARN;
return dma_alloc_attrs(dev, size, dma_addr, gfp, attrs);
}
dma_alloc_attrs();
dma_alloc_from_dev_coherent(); // 如果dts有reserved memory会走这个函数
dev_get_coherent_memory();
return dev->dma_mem // 直接返回reserved-memory中分配的地址了
return cpu_addr;
// dev->mem的分配:
dma_init_reserved_memory();
ops->device_init(dma_reserved_default_memory, NULL);
static const struct reserved_mem_ops rmem_dma_ops = {
.device_init = rmem_dma_device_init,
};
rmem_dma_device_init();
dma_init_coherent_memory();
dma_assign_coherent_memory();
dev->dma_mem = mem;
看起来如果在 dts 中分配了 reserved-memory,dma_alloc_coherent和dma_alloc_wc流程是一样的,都会走dma_alloc_from_dev_coherent从 reserved-memory 中分配空间(这块区域是 cached?buffer?,rts3917 启动中有打印:Memory policy: Data cache writeback是否与 reserved memory 有关系)
所以 rts_fb.c 中有dma_sync_single_for_device?
| 是否启用 cache | 是否启用 buffer | 说明 |
|---|---|---|
| 0 | 0 | 无 cache,无写缓冲 读、写都直达外设硬件 |
| 0 | 1 | 无 cache,有写缓冲 读操作直达外设硬件;写操作,CPU 将数据写入到写缓冲后继续运行,由写缓冲进行写回操作。 |
| 1 | 0 | 有 cache,写通模式 write through。 数据要同时写入 cache 和内存,所以 cache 和内存中的数据保持一致。 |
| 1 | 1 | 有 cache,写回模式 write back 新数据只是写入 cache ,不会立刻写入内存。 |