SPI 协议介绍
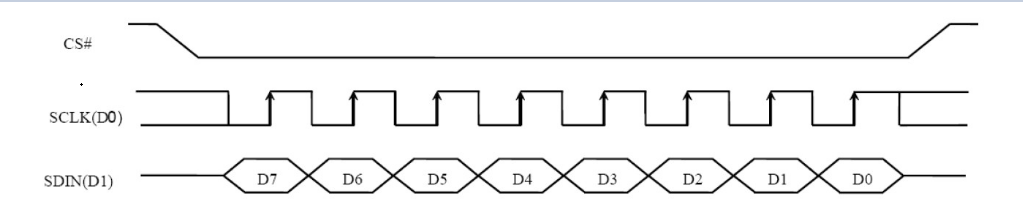
CPOL:表示 SPICLK 的初始电平,0 为低电平,1 为高电平
CPHA:表示相位,即第一个还是第二个时钟沿采样数据,0 为第一个时钟沿,1 为第二个时钟沿
| CPOL | CPHA | 模式 | 含义 |
|---|---|---|---|
| 0 | 0 | 0 | SPICLK 初始电平为低电平,在第一个时钟沿采样数据 |
| 0 | 1 | 1 | SPICLK 初始电平为低电平,在第二个时钟沿采样数据 |
| 1 | 0 | 2 | SPICLK 初始电平为高电平,在第一个时钟沿采样数据 |
| 1 | 1 | 3 | SPICLK 初始电平为高电平,在第二个时钟沿采样数据 |
我们常用的是模式 0 和模式 3,因为它们都是在上升沿采样数据,不用去在乎时钟的初始电平是什么,只要在上升沿采集数据就行。
SPI driver
spi_controller
struct spi_controller {
struct device dev;
struct list_head list;
s16 bus_num;
u16 num_chipselect;
u16 dma_alignment;
u32 mode_bits;
u32 buswidth_override_bits;
u32 bits_per_word_mask;
u32 min_speed_hz;
u32 max_speed_hz;
u16 flags;
bool devm_allocated;
union {
bool slave;
bool target;
};
size_t (*max_transfer_size)(struct spi_device *spi);
size_t (*max_message_size)(struct spi_device *spi);
struct mutex io_mutex;
struct mutex add_lock;
spinlock_t bus_lock_spinlock;
struct mutex bus_lock_mutex;
bool bus_lock_flag;
int (*setup)(struct spi_device *spi);
int (*set_cs_timing)(struct spi_device *spi);
int (*transfer)(struct spi_device *spi,
struct spi_message *mesg);
void (*cleanup)(struct spi_device *spi);
bool (*can_dma)(struct spi_controller *ctlr,
struct spi_device *spi,
struct spi_transfer *xfer);
struct device *dma_map_dev;
struct device *cur_rx_dma_dev;
struct device *cur_tx_dma_dev;
bool queued;
struct kthread_worker *kworker;
struct kthread_work pump_messages;
spinlock_t queue_lock;
struct list_head queue;
struct spi_message *cur_msg;
struct completion cur_msg_completion;
bool cur_msg_incomplete;
bool cur_msg_need_completion;
bool busy;
bool running;
bool rt;
bool auto_runtime_pm;
bool cur_msg_mapped;
bool fallback;
bool last_cs_mode_high;
s8 last_cs[SPI_CS_CNT_MAX];
u32 last_cs_index_mask : SPI_CS_CNT_MAX;
struct completion xfer_completion;
size_t max_dma_len;
int (*optimize_message)(struct spi_message *msg);
int (*unoptimize_message)(struct spi_message *msg);
int (*prepare_transfer_hardware)(struct spi_controller *ctlr);
int (*transfer_one_message)(struct spi_controller *ctlr,
struct spi_message *mesg);
int (*unprepare_transfer_hardware)(struct spi_controller *ctlr);
int (*prepare_message)(struct spi_controller *ctlr,
struct spi_message *message);
int (*unprepare_message)(struct spi_controller *ctlr,
struct spi_message *message);
union {
int (*slave_abort)(struct spi_controller *ctlr);
int (*target_abort)(struct spi_controller *ctlr);
};
void (*set_cs)(struct spi_device *spi, bool enable);
int (*transfer_one)(struct spi_controller *ctlr, struct spi_device *spi,
struct spi_transfer *transfer);
void (*handle_err)(struct spi_controller *ctlr,
struct spi_message *message);
const struct spi_controller_mem_ops *mem_ops;
const struct spi_controller_mem_caps *mem_caps;
struct gpio_desc **cs_gpiods;
bool use_gpio_descriptors;
s8 unused_native_cs;
s8 max_native_cs;
struct spi_statistics __percpu *pcpu_statistics;
struct dma_chan *dma_tx;
struct dma_chan *dma_rx;
void *dummy_rx;
void *dummy_tx;
int (*fw_translate_cs)(struct spi_controller *ctlr, unsigned cs);
bool ptp_sts_supported;
unsigned long irq_flags;
bool queue_empty;
bool must_async;
bool defer_optimize_message;
};
list: spi controller global list。
bus_num: SoC 上某个 spi controller 的编号。
num_chipselect: 用来表示 spi slaves 的编号,每个 slave 都有一个 chipselect signal。
dma_alignment: 有些 spi controller 对 dma buffer 有 alignment 要求,vendor driver 设置。
mode_bits: 用来表示 spi controller 支持的 mode,在 uapi/linux/spi/spi.h 中定义,vendor driver 设置。
bits_per_word_mask: 用来表示 spi controller 支持的 bits_per_word,vendor driver 设置。
min/max_speed_hz: 用来表示 spi controller 支持的 min/max speed,vendor driver 设置。
flags: 额外的 flags,支持的有:
#define SPI_CONTROLLER_HALF_DUPLEX BIT(0) /* Can't do full duplex */
#define SPI_CONTROLLER_NO_RX BIT(1) /* Can't do buffer read */
#define SPI_CONTROLLER_NO_TX BIT(2) /* Can't do buffer write */
#define SPI_CONTROLLER_MUST_RX BIT(3) /* Requires rx */
#define SPI_CONTROLLER_MUST_TX BIT(4) /* Requires tx */
#define SPI_CONTROLLER_GPIO_SS BIT(5) /* GPIO CS must select slave */
#define SPI_CONTROLLER_SUSPENDED BIT(6) /* Currently suspended */
#define SPI_CONTROLLER_MULTI_CS BIT(7)
transfer: 向 queue 中增加 spi message, 由 spi core 提供,默认实现为 spi_queued_transfer。
can_dma: 是否支持 dma.
queued: 如果支持 spi core 的 queue 机制,transfer 函数由 spi core 提供,则 spi core 把 queued 置为 1.
transfer_one_message: 如果 vendor driver 没实现,默认实现为 spi_transfer_one_message.
max_transfer_size/max_message_size: spi controller 支持的 max transfer size/max message size 回调,vendor driver 设置。
setup: 设定 spi controller mode, clk 等等。
set_cs_timing: optional, 设定 cs timing 的回调。
prepare_message/unprepare_message: optional, 为 spi message 传输前的准备工作,比如设定 dma mapping 等。
transfer_one: 传输一条 spi_transfer, 传输完成需要调用 spi_finalize_current_transfer,和 transfer_one_message 互斥。
spi_transfer, spi_message
在 SPI 子系统中,用 spi_transfer 结构体描述一个传输,用 spi_message 管理整个传输。可以构造多个 spi_transfer 结构体,把它们放入一个 spi_message 里面。
SPI 传输时,发出 N 个字节,就可以同时得到 N 个字节。
- 即使只想读 N 个字节,也必须发出 N 个字节:可以发出 0xff
- 即使只想发出 N 个字节,也会读到 N 个字节:可以忽略读到的数据。
struct spi_message {
struct list_head transfers;
struct spi_device *spi;
unsigned is_dma_mapped:1;
bool prepared;
int status;
void (*complete)(void *context);
void *context;
unsigned frame_length;
unsigned actual_length;
struct list_head queue;
struct list_head resources;
};
transfers: 一个 spi_message 可以包含多个 spi_transfer,组成一个链表。
spi: 传输 message 到某个 spi device。
is_dma_mapped: 找不到 spi core 哪里使用了该 field?? 是否
prepared: 是否调用了 ctrl->prepare_message()。
status: 当前 message 的 status,0 表示正常,负数表示异常。
complete: 传输完成后的回调。
context: 传递给 complete 的参数。
frame_length: 当前 message 的要传输的总字节数。
actual_length: 当前 message 实际已经传输的字节数。
struct spi_transfer {
const void *tx_buf;
void *rx_buf;
unsigned len;
dma_addr_t tx_dma;
dma_addr_t rx_dma;
struct sg_table tx_sg;
struct sg_table rx_sg;
unsigned cs_change:1;
unsigned tx_nbits:3;
unsigned rx_nbits:3;
#define SPI_NBITS_SINGLE 0x01 /* 1-bit transfer */
#define SPI_NBITS_DUAL 0x02 /* 2-bit transfer */
#define SPI_NBITS_QUAD 0x04 /* 4-bit transfer */
u8 bits_per_word;
u8 word_delay_usecs;
u16 delay_usecs;
u16 cs_change_delay;
u8 cs_change_delay_unit;
u32 speed_hz;
u16 word_delay;
u32 effective_speed_hz;
struct list_head transfer_list;
};
tx_buf/rx_buf: 发送/接收数据缓冲区。
len: 发送/接收数据的长度。
tx_dma/rx_dma: 发送/接收数据缓冲区的 dma 地址。
tx_sg/rx_sg: 发送/接收数据缓冲区的 scatterlist。
cs_change: 传输完成后是否要改变 cs 信号,consumer 设定。
cs_change_delay: 当 cs_change 置起,传输完成后,cs 信号 deassert 到 assert 的 delay 时间,consumer 设定。
tx_nbits/rx_nbits: 每秒传输几 bits,有 SPI_NBITS_SINGLE, SPI_NBITS_DUAL, SPI_NBITS_QUAD 三种。
bits_per_word: 一次 SPI 传输中发送/接收的每个数据单元的大小。
delay_usecs: 传输开始前的 delay。
speed_hz: 传输速度。
SPI 设备树
SPI Master
必须的属性如下:
- address-cells:这个 SPI Master 下的 SPI 设备,需要多少个 cell 来表述它的片选引脚
- size-cells:必须设置为 0
- compatible:根据它找到 SPI Master 驱动
可选的属性如下:
- cs-gpios:SPI Master 可以使用多个 GPIO 当做片选,可以在这个属性列出那些 GPIO
- num-cs:片选引脚总数
SPI Device
必须的属性如下:
- compatible:根据它找到 SPI Device 驱动
- reg:用来表示它使用哪个片选引脚
- spi-max-frequency:必选,该 SPI 设备支持的最大 SPI 时钟
可选的属性如下:
- spi-cpol:这是一个空属性 (没有值),表示 CPOL 为 1,即平时 SPI 时钟为低电平
- spi-cpha:这是一个空属性 (没有值),表示 CPHA 为 1),即在时钟的第 2 个边沿采样数据
- spi-cs-high:这是一个空属性 (没有值),表示片选引脚高电平有效
- spi-3wire:这是一个空属性 (没有值),表示使用 SPI 三线模式
- spi-lsb-first:这是一个空属性 (没有值),表示使用 SPI 传输数据时先传输最低位 (LSB)
- spi-tx-bus-width:表示有几条 MOSI 引脚;没有这个属性时默认只有 1 条 MOSI 引脚
- spi-rx-bus-width:表示有几条 MISO 引脚;没有这个属性时默认只有 1 条 MISO 引脚
- spi-rx-delay-us:单位是毫秒,表示每次读传输后要延时多久
- spi-tx-delay-us:单位是毫秒,表示每次写传输后要延时多久
示例:
spi@f00 {
#address-cells = <1>;
#size-cells = <0>;
compatible = "fsl,mpc5200b-spi","fsl,mpc5200-spi";
reg = <0xf00 0x20>;
interrupts = <2 13 0 2 14 0>;
interrupt-parent = <&mpc5200_pic>;
ethernet-switch@0 {
compatible = "micrel,ks8995m";
spi-max-frequency = <1000000>;
reg = <0>;
};
codec@1 {
compatible = "ti,tlv320aic26";
spi-max-frequency = <100000>;
reg = <1>;
};
};
spidev 的使用 (SPI 用户态 API)
- 内核驱动:
drivers\spi\spidev.c - 内核提供的测试程序:
tools\spi\spidev_fdx.c - 内核文档:
Documentation\spi\spidev
spidev 驱动程序分析
内核驱动:drivers\spi\spidev.c
spidev_write();
spidev_sync_write();
spidev_sync();
spidev_read();
spidev_sync_read();
spidev_sync();
spidev_ioctl();
// 在应用层通过 ioctl(fd, SPI_IOC_MESSAGE(x), xfer) 来调用,进行 spi 传输。参考 spidev_fdx.c
spidev 应用程序分析
内核提供的测试程序:tools\spi\spidev_fdx.c
使用方法:
spidev_fdx [-h] [-m N] [-r N] /dev/spidevB.D
h: 打印用法
m N:先写 1 个字节 0xaa,再读 N 个字节,**注意:**不是同时写同时读
r N:读 N 个字节
spidev 缺点
使用 read、write 函数时,只能读、写,这是半双工方式。
使用 ioctl 可以达到全双工的读写。
但是 spidev 有 2 个缺点:
- 不支持中断
- 只支持同步操作,不支持异步操作:就是 read/write/ioctl 这些函数只能执行完毕才可返回
Data structure and APIs
// include/linux/spi/spi.h
static inline int spi_write(struct spi_device *spi, const void *buf, size_t len);
static inline int spi_read(struct spi_device *spi, void *buf, size_t len);
extern int spi_write_then_read(struct spi_device *spi, const void *txbuf, unsigned n_tx, void *rxbuf, unsigned n_rx);
static inline ssize_t spi_w8r8(struct spi_device *spi, u8 cmd);
static inline ssize_t spi_w8r16(struct spi_device *spi, u8 cmd);
static inline ssize_t spi_w8r16be(struct spi_device *spi, u8 cmd);
static inline int spi_sync_transfer(struct spi_device *spi, struct spi_transfer *xfers, unsigned int num_xfers);
extern int spi_async(struct spi_device *spi, struct spi_message *message);
extern int spi_sync(struct spi_device *spi, struct spi_message *message);
所有的传输函数都是 spi_async 和 spi_sync 的封装。
流程分析
spi driver 初始化:
spi_alloc_host();
spi_register_controller();
spi_controller_initialize_queue();
ctlr->transfer = spi_queued_transfer;
ctlr->transfer_one_message = spi_transfer_one_message;
spi_init_queue();
kthread_init_work(&ctlr->pump_messages, spi_pump_messages);
spi_start_queue();
// 进入 spi_pump_messages
kthread_queue_work(ctlr->kworker, &ctlr->pump_messages);
spi_pump_messages();
// 此时 ctlr->queue 为空,进入 idle 状态返回。
传输函数流程分析:
spi_sync()
// 这里根据 queue_empty 决定传输方式
// 如果此时 queue 是 empty 的,那么直接传输
// 如果此时 queue 中还有消息没有发完,那么将当前消息也放入 queue,并阻塞等待完成
__spi_transfer_message_noqueue()/spi_async_locked()
// sync 处理
__spi_transfer_message_noqueue()
__spi_pump_transfer_message()
// async 处理
spi_async_locked()
ctlr->transfer()
spi_queued_transfer() // ctlr->transfer()
list_add_tail(&msg->queue, &ctlr->queue)
kthread_queue_work(ctlr->kworker, &ctlr->pump_messages) // 进入 spi_pump_messages
// return
spi_pump_messages()
__spi_pump_messages();
// 取出第一条 message
msg = list_first_entry(&ctlr->queue, struct spi_message, queue);
// 这里开始 sync 和 async 的处理就一样了
__spi_pump_transfer_message();
static int __spi_pump_transfer_message(struct spi_controller *ctlr,
struct spi_message *msg, bool was_busy)
{
struct spi_transfer *xfer;
int ret;
/// 第一次传输 was_busy 为 false,后面都为 true, resume 唤醒
if (!was_busy && ctlr->auto_runtime_pm)
pm_runtime_get_sync(ctlr->dev.parent);
if (!was_busy && ctlr->prepare_transfer_hardware)
ret = ctlr->prepare_transfer_hardware(ctlr);
/// 如果硬件对单次 transfer size 有限制,则需要将 transfers 拆分成多个 transfers
spi_split_transfers_maxsize(ctlr, msg,
spi_max_transfer_size(msg->spi),
GFP_KERNEL | GFP_DMA);
if (ctlr->prepare_message) {
ctlr->prepare_message(ctlr, msg);
msg->prepared = true;
}
spi_map_msg(ctlr, msg);
WRITE_ONCE(ctlr->cur_msg_incomplete, true);
WRITE_ONCE(ctlr->cur_msg_need_completion, false);
reinit_completion(&ctlr->cur_msg_completion);
ctlr->transfer_one_message(ctlr, msg);
WRITE_ONCE(ctlr->cur_msg_need_completion, true);
if (READ_ONCE(ctlr->cur_msg_incomplete))
wait_for_completion(&ctlr->cur_msg_completion);
return 0;
}
static int spi_transfer_one_message(struct spi_controller *ctlr,
struct spi_message *msg)
{
struct spi_transfer *xfer;
bool keep_cs = false;
int ret = 0;
xfer = list_first_entry(&msg->transfers, struct spi_transfer,
transfer_list);
spi_set_cs(msg->spi, !xfer->cs_off, false);
list_for_each_entry(xfer, &msg->transfers, transfer_list) {
if ((xfer->tx_buf || xfer->rx_buf) && xfer->len) {
reinit_completion(&ctlr->xfer_completion);
fallback_pio:
spi_dma_sync_for_device(ctlr, xfer);
ret = ctlr->transfer_one(ctlr, msg->spi, xfer);
/// 正常 transfer_one return 1, 在 spi_transfer_wait 中等待中断调用 spi_finalize_current_transfer
if (ret > 0)
spi_transfer_wait(ctlr, msg, xfer);
spi_dma_sync_for_cpu(ctlr, xfer);
}
// ...
msg->actual_length += xfer->len;
}
out:
if (ret != 0 || !keep_cs)
spi_set_cs(msg->spi, false, false); // cs 拉低
spi_finalize_current_message(ctlr);
return ret;
}