3.3 数据格式
Intel用术语字来表示16位数据类型。
32位:双字。
64位:四字。
3.4 访问信息

%rbp是帧指针。
生成1字节和2字节数字的指令会保持剩下的字节不变;
生成4字节数字的指令会把高位的4个字节置为0。
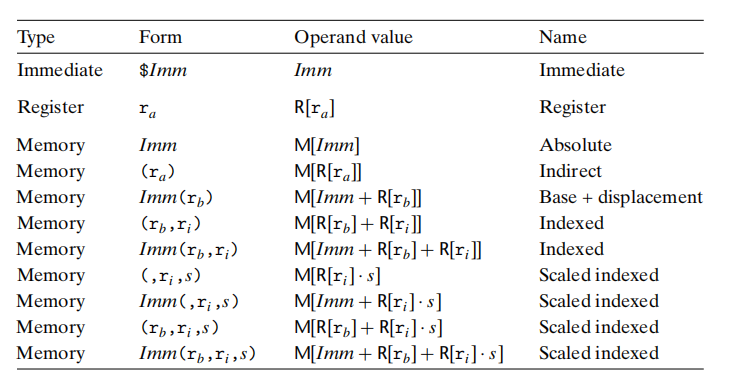
3.4.1 操作数指示符
3.4.2 数据传送指令
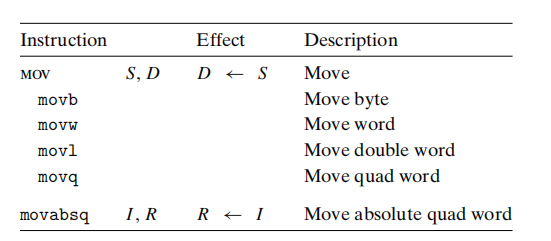

MOV S, D: S->D
传送指令和的两个操作数不能都指向内存地址。
movabsq: 常规的movq指令只能以表示为32位补码数字的立即数作为源操作数。然后把这个值符号扩展得到64位的值,放到目的位置。
movabsq指令能够以任意64位立即数作为源操作数,并且只能以寄存器作为目的。
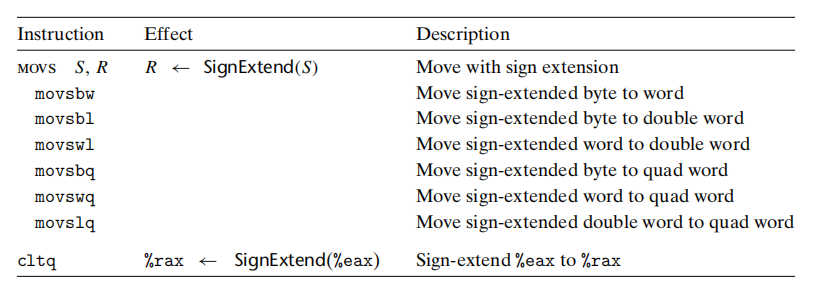
MOVZ S, R: 零扩展(S)->RMOVS S, R: 符号扩展(S)->R
这两个指令目的只能是寄存器。
cltq: 符号扩展(%eax)->%rax, 把%eax符号扩展到%rax。
3.4.4 压入和弹出栈数据

练习题 3.2
内存引用总是以4字节寄存器给出,比如%rax。
练习题 3.3
movl %eax, %rdx: 目的寄存器%rdx长度不匹配,应该为%edx。
3.5算术和逻辑操作
图3-10:
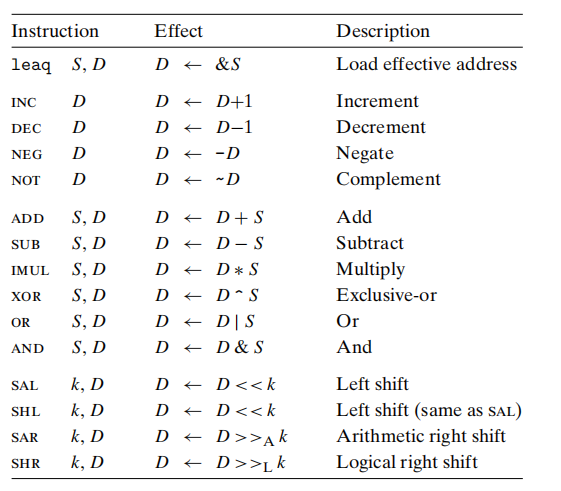
3.5.1 加载有效地址
如果%rdx保存的值为xleaq 7(%rdx, %rdx, 4), %rax: 将%rax寄存器的值设为5x+7。
指令形式是从内存读数据到寄存器,但实际上根本没有引用内存。
3.5.3 移位操作
移位量可以是一个立即数,或者放在单字节寄存器%cl中。(只允许以这个特定的寄存器)
3.5.5 特殊的算术操作
//TODO:
3.6 控制
3.6.1 条件码
CF: 进位标志。
ZF: 零标志。
SF: 符号标志。
OF: 溢出标志。
leaq指令不改变任何条件码。
图3-10中的算术和逻辑操作都会改变条件码。
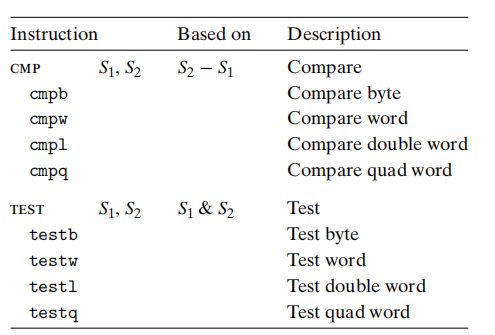
还有两类指令只设置条件码而不改变任何其他寄存器。cmp和test。cmp根据两个操作数之差(SUB)设置条件码。test根据两个操作数的与(AND)来设置条件码。
3.6.2 访问条件码
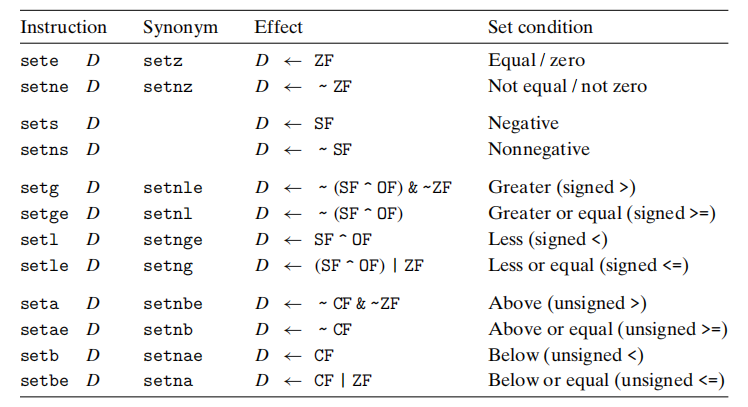
set指令,根据条件码将一个字节设置为0或1。
3.6.3 跳转指令
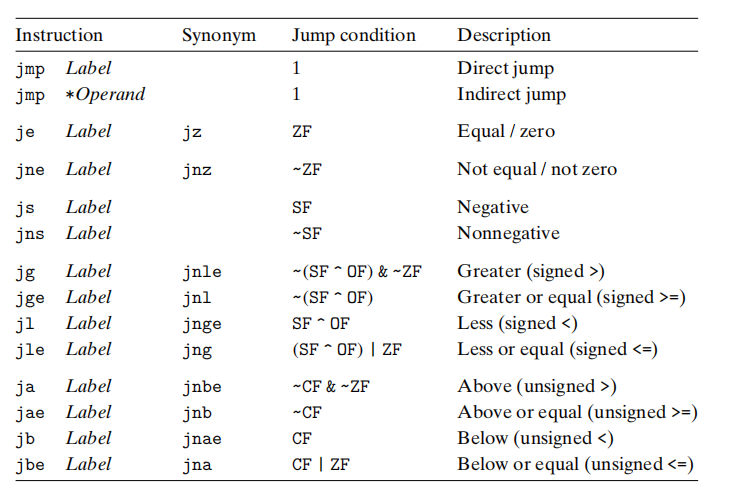
直接跳转: jmp + <label>
间接跳转: 寄存器中保存的值为跳转目标:jmp *%rax; 内存中的值为跳转目标:jmp *Operand
带条件码的跳转指令只能是直接跳转
3.6.4 跳转指令的编码
分相对地址和绝对地址, 一般都是使用相对地址。
相对地址跳转为pc指针加上偏移量,e.g.
3: eb 03 jmp 8 <loop+0x8>
5: 48 d1 f8 sar %rax
当执行到地址3的时候,执行了jmp指令,跳转地址为当前的pc指针(0x5)+跳转的偏移量(0x3)=0x8。
3.6.5 用条件控制来实现条件分支
3.6.6 用条件传送来实现条件分支
上面两者的区别是,条件控制利用类似goto风格的汇编代码,当条件满足时执行一条路径,当条件不满足则执行另一条路径。
而条件传送会同时执行两个分支的结果,再根据需要的条件选择一个结果。这种按顺序执行可以避免预测错误带来的性能下降。因为CPU执行指令通过流水线来提高性能。
条件控制汇编伪代码:
if !(test-expr)
goto false;
v = then-expr;
goto done;
false:
v = else-expr;
done:
条件传送汇编伪代码:
v = then-expr;
ve = else-expr;
t = test-expr;
if (!t) v= ve;
条件传送指令:

不过gcc还是更多地使用了条件控制转移。
3.6.7 循环
do-while循环
loop:
body-statement
t = test-expr;
if (t)
goto loop;
while循环
有两种形式的汇编代码:
1.jump to middle
goto test;
loop:
body-statement
test:
t = test-expr;
if (t)
goto loop;
2.guarded-do
较高的优化等级,比如-O1, GCC会采取这种策略。
t = test-expr;
if (!t)
goto done;
loop:
body-statement
t = test-expr;
if (t)
goto loop;
done:
for循环
和while循环两种结构一致。
switch
GCC会根据switch的情况来产生不同的汇编代码。
当switch的数量比较多,并且值的范围跨度比较小时,会使用跳转表。跳转表的时间复杂度是O(1)。
而当switch的数量比较少,或值的范围跨度比较大时,会将switch翻译成if-else的汇编。
switch C code:
void switch_eg(long x, long n, long *dest)
{
long val = x;
switch (n) {
case 100:
val *= 13;
break;
case 102:
val += 10;
/* Fall through */
case 103:
val += 11;
break;
case 104:
case 106:
val *= val;
break;
default:
val = 0;
}
*dest = val;
}
编译器在编译switch语句后,会生成.rodata的跳转表:
.section .rodata
.align 8 Align address to multiple of 8
.L4:
.quad .L3 Case 100: loc_A
.quad .L8 Case 101: loc_def
.quad .L5 Case 102: loc_B
.quad .L6 Case 103: loc_C
.quad .L7 Case 104: loc_D
.quad .L8 Case 105: loc_def
.quad .L7 Case 106: loc_D
汇编code:
switch_eg:
subq $100, %rsi Compute index = n-100
cmpq $6, %rsi Compare index:6
ja .L8 If >, goto loc_def
jmp *.L4(,%rsi,8) Goto *jg[index]
.L3: loc_A:
leaq (%rdi,%rdi,2), %rax 3*x
leaq (%rdi,%rax,4), %rdi val = 13*x
jmp .L2 Goto done
.L5: loc_B:
addq $10, %rdi x = x + 10
.L6: loc_C:
addq $11, %rdi val = x + 11
jmp .L2 Goto done
.L7: loc_D:
imulq %rdi, %rdi val = x * x
jmp .L2 Goto done
.L8: loc_def:
movl $0, %edi val = 0
.L2: done:
movq %rdi, (%rdx) *dest = val
ret Return
3.7 过程
3.7.1 运行时栈
栈结构:

3.7.2 转移控制
call指令会做三件事,1. 把返回地址压入栈中,2. 栈指针+8, 3. 设置%rip到新函数的第一条指令。
3.7.3 数据传送
前六个函数参数会保存在寄存器中传递,第七个参数之后会保存在当前函数栈帧中。无论是什么数据类型大小都会占8个字节, 参数编号越大,在栈帧中的地址越高。
因此第七个参数保存在%rsp+8, 第八个参数%rsp+16… %rsp保存的是返回地址。
再往下就是被调用函数的栈帧,最高地址保存的是调用函数的帧指针(帧指针是可选的),后面是需要被调用者保存的一些寄存器和局部变量。
3.7.4 栈上的局部存储
如果函数中对一个局部变量使用了地址运算符&, 那么必须能够为他产生一个地址。因此该变量必须存放在栈中。
如果寄存器中能保存下局部变量,可能不会使用到栈。
参考图3.32-33的例子。
long call_proc()
{
long x1 = 1; long x2 = 2;
short x3 = 3; char x4 = 4;
proc(x1, &x1, x2, &x2, x3, &x3, x4, &x4);
return (x1+x2)*(x3+x4);
}
因为对x1-x4使用了地址运算符,那么必须将他们放到栈中。
movq $1, 24(%rsp) # store 1 in &x1
movl $2, 20(%rsp) # store 1 in &x1
...
leaq 24(%rsp), %rsi # pass &x1 as arguement 2
试想一下如果把x1放到寄存器中movq $1, %rsi,但寄存器没有地址,无法取到x1的地址。
3.7.6 递归过程
3.8 数组的分配和访问
int A1[3] 保存3个int整型的数组。int *A2[3] 保存3个int指针的数组。int (*A3)[3] 一个指针,指向包含3个int整型的数组。int (*A4[3]) 同A2。
3.9 异质的数据结构
3.9.1 结构struct
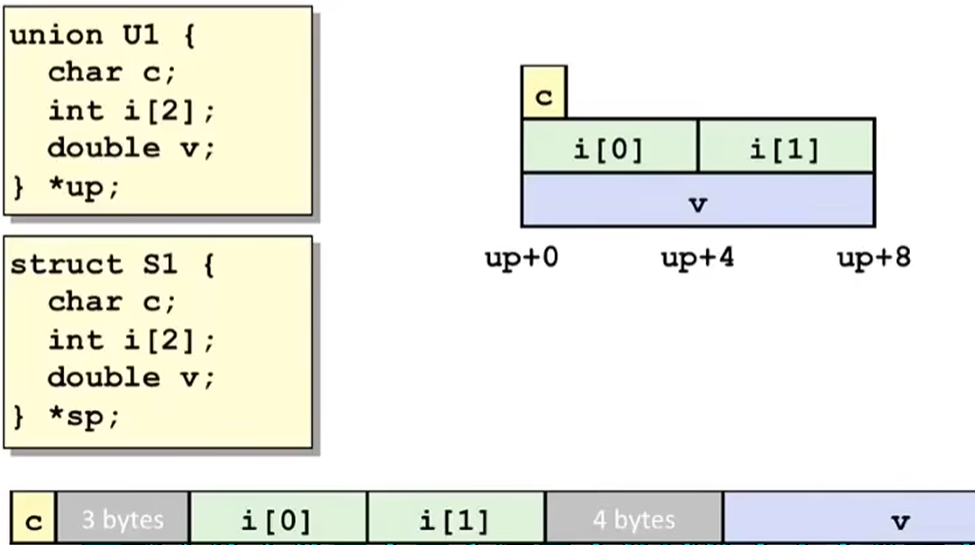
3.9.2 联合union
这张图展示了struct和union的区别。
union的大小为其中最大的某个变量。
3.9.3 数据对齐
- 任何K字节的基本对象的地址必须是K的倍数。比如int的起始地址必须是4字节对齐,double8字节。
- 结构体总的大小以包含最大的数据类型对齐,比如包含了int,那么结构体至少需要4字节对齐。
3.10.3 内存越界引用和缓冲区溢出
缓冲区溢出(buffer overflow)。传入的字符串长度超过了buf数组的长度。导致栈上的其他数据被替换。
char *gets(char *s)
{
int c;
char *dest = s;
while ((c = getchar()) != '\n' && c != EOF)
*dest++ = c;
if (c == EOF && dest == s)
/* No characters read */
return NULL;
*dest++ = ’\0’; /* Terminate string */
return s;
}
/* Read input line and write it back */
void echo()
{
char buf[8]; /* Way too small! */
gets(buf);
puts(buf);
}
3.10.4 对抗缓冲区溢出攻击
栈随机化ASLR
在程序开始时,在栈上分配一段0~n字节之间的随机大小空间。程序不使用这段空间。

栈破坏原则
在栈帧中任何局部缓冲区与栈的状态间存储一个金丝雀值(canary),也成为哨兵值(guard value)。
在退出函数前检查该值是否被污染。
GCC中对应的编译选项为-fstack-protector, 现在基本是默认开启的。
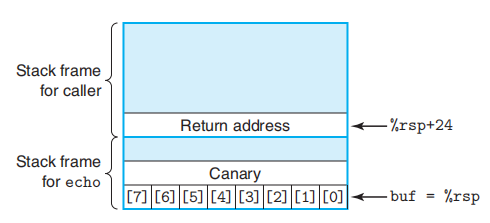
对应的x86汇编代码会长这样:
mov %fs:0x28,%rax # 生成金丝雀值,并保存到%rax。
mov %rax,0x8(%rsp) # 将%rax保存到栈中
...
mov 0x8(%rsp),%rax # 读出栈中的金丝雀值
xor %fs:0x28,%rax # 与原来的金丝雀值对比
...
call 400580 <__stack_chk_fail@plt> # 如果不一致跳转到错误函数
限制可执行代码区域
限制只有保存编译器产生的代码那部分内存才需要是可执行的,其他部分可以被限制为只允许读和写。
3.10.5 支持变长栈帧
// TODO:
3.11 浮点代码
// TODO: