这篇文章是阅读 OSTEP 3~11 的笔记,主要讲的是 Virtualization 中 Virtualize CPU 的部分。
Chapter4 Process
4.2 Process API
一般 OS 会提供以下的进程 API 来操作进程:
- Create: 创建进程。
- Destory: 结束进程。
- Wait: Wait a process to stop running. 等待进程结束。
- Miscellaneous Control: Suspend/Resume… 休眠,唤醒等等。
- Status: 查看进程状态。
4.3 Process Creation
- 首先 OS 将存储在 disk or SSD 的 program 程序加载进 memory 内存。 这边有两种方式,一种是在运行前把 code 和 static data 全部加载进内存。现代操作系统一般会使用第二种方式,懒加载,只加载即将使用的 code 和 data。
- 分配栈。
- 分配堆。
- 分配三个文件描述符,标准输入 0,标准输出 1,错误 2。
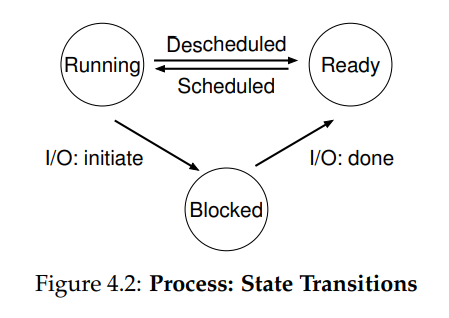
4.4 Process Status
进程的状态有:
- Running: 正在使用 CPU 执行指令。
- Ready: 进程就绪态。
- Blocked: 比如进程在和 disk IO 交互,这时会把 CPU 让出给其他进程使用,进入阻塞态。
4.5 Data Struct
PCB, Process Control Block 用来描述进程的数据结构。
参考 xv6 中描述进程的数据结构:
struct proc {
char *mem; // Start of process memory
uint sz; // Size of process memory
char *kstack; // Bottom of kernel stack
// for this process
enum proc_state state; // Process state
int pid; // Process ID
struct proc *parent; // Parent process
void *chan; // If !zero, sleeping on chan
int killed; // If !zero, has been killed
struct file *ofile[NOFILE]; // Open files
struct inode *cwd; // Current directory
struct context context; // Switch here to run process
struct trapframe *tf; // Trap frame for the current interrupt
};
Chapter5 Process API
5.1 fork() system call
pid_t fork(void)
fork 系统调用用来创建进程。子进程返回 0,父进程返回子进程 PID。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(int argc, char *argv[]) {
printf("hello (pid:%d)\n", (int) getpid());
int rc = fork();
if (rc < 0) {
// fork failed
fprintf(stderr, "fork failed\n");
exit(1);
} else if (rc == 0) {
// child (new process)
printf("child (pid:%d)\n", (int) getpid());
} else {
// parent goes down this path (main)
printf("parent of %d (pid:%d)\n", rc, (int) getpid());
}
return 0;
}
prompt> ./p1
hello (pid:29146)
parent of 29147 (pid:29146) # 这条和下面一条出现顺序随机
child (pid:29147)
prompt>
5.2 wait() system call
pid_t wait(int *wstatus)
wait 系统调用会 block 等待子进程结束。wstatus可以传入 NULL,也可以传入一个指针,通过进一步其他的 API 来获取子进程状态。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
int main(int argc, char *argv[]) {
printf("hello (pid:%d)\n", (int) getpid());
int rc = fork();
if (rc < 0) { // fork failed; exit
fprintf(stderr, "fork failed\n");
exit(1);
} else if (rc == 0) { // child (new process)
printf("child (pid:%d)\n", (int) getpid());
} else { // parent goes down this path
int rc_wait = wait(NULL);
printf("parent of %d (rc_wait:%d) (pid:%d)\n", rc, rc_wait, (int) getpid());
}
return 0;
}
prompt> ./p2
hello (pid:29266)
child (pid:29267) # 这条和吓一条顺序是确定的
parent of 29267 (rc_wait:29267) (pid:29266)
prompt>
5.3 exec() system call
exec()系列系统调用,直接在当前进程加载另一个 program, 运行另一个进程,不返回。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/wait.h>
int main(int argc, char *argv[]) {
printf("hello (pid:%d)\n", (int) getpid());
int rc = fork();
if (rc < 0) { // fork failed; exit
fprintf(stderr, "fork failed\n");
exit(1);
} else if (rc == 0) { // child (new process)
printf("child (pid:%d)\n", (int) getpid());
char *myargs[3];
myargs[0] = strdup("wc"); // program: "wc"
myargs[1] = strdup("p3.c"); // arg: input file
myargs[2] = NULL; // mark end of array
execvp(myargs[0], myargs); // runs word count
printf("this shouldn’t print out");
} else { // parent goes down this path
int rc_wait = wait(NULL);
printf("parent of %d (rc_wait:%d) (pid:%d)\n", rc, rc_wait, (int) getpid());
}
return 0;
}
prompt> ./p3
hello (pid:29383)
child (pid:29384)
29 107 1030 p3.c
parent of 29384 (rc_wait:29384) (pid:29383)
prompt>
Others
kill(), signal(), pipe()
Chapter6 Limited Direct Execution
6.1 Problem#1 Restricted Operations
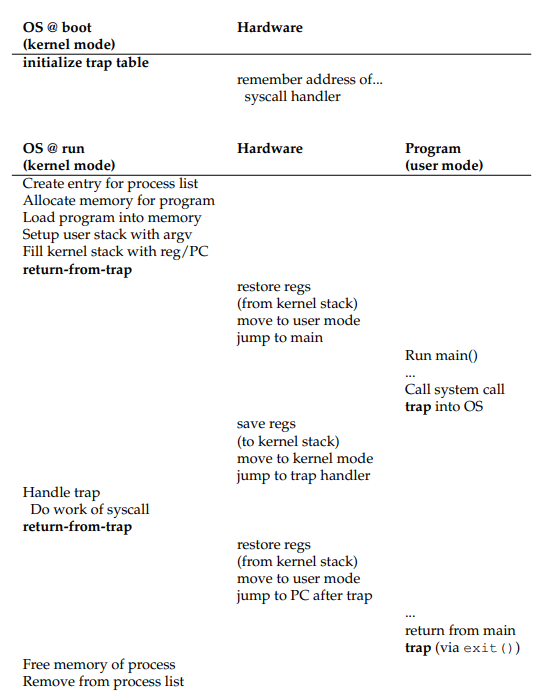
User space 要与 kernel space 隔离,通过 system call 的方式来访问硬件。
OS 启动,以及 user 程序 system call 与 kernel 交互流程:
6.2 Problem#2 Switching Between Processes
- Cooperative Approach:协作式,等 process 自己主动交出 CPU 控制权。
- Non-cooperative Approach: 抢占式,OS 通过 timer interrupt,给每个 process 一定的时间片执行,到了 timer 的时间就要交出 CPU 控制权。
Context Switch
进程 A 和进程 B 进行切换的上下文交换过程:
注意每个进程都有自己的 kernel stack。

Summary
- CPU 跑 OS 需要支持user mode和kernel mode。
- user mode 使用system call trap into kernel。
- kernel 启动过程中准备好了trap table。
- OS 完成 system call 后,通过return-from-trap指令返回 user code。
- kernel 利用timer interrupt来防止一个用户进程一直占用 CPU。
- 进程间交换需要context switch。
Chapter7 Scheduling: Introduction
几个衡量性能的指标:
转换时间=完成时间-到达时间
\(T_{turnaround}=T_{completion}-T_{arrival}\)
响应时间=开始执行时间-到达时间
\(T_{response}=T_{firstrun}-T_{arrival}\)
7.3 FIFO
先进先出原则,如果进程一起到来,按先后顺序执行。
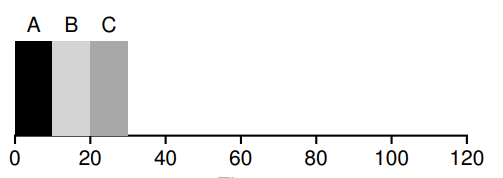
存在的问题是,如果前面的进程运行时间长,平均的 turnaround 时间就会变得很长:
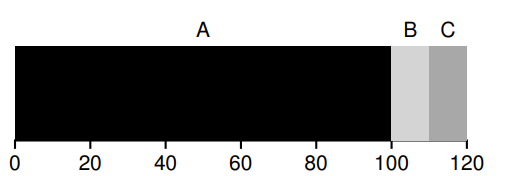
7.4 Shortest Job first(SJF)
先执行时间短的进程。
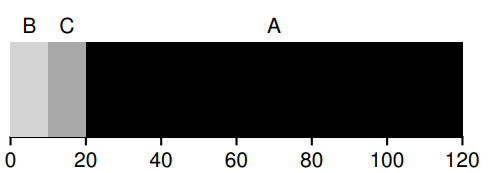
存在的问题是,如果几个进程不是同时到来,先执行到时间长的进程,仍然有和 FIFO 调度一样的问题:

7.5 Shortest Time-to-Completion First(STCF)
在 SJF 调度上加入抢占式机制。当有新进程到来时,调度器会判断谁的执行时间更短,来执行时间更短的进程。

7.7 Round Robin
Response time 比前面的调度算法都好。
每个进程执行一段时间后切换。要考虑 context switch 的消耗,选择合适的时间片。
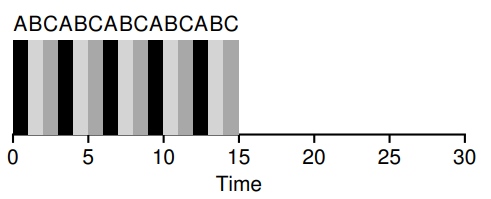
7.8 Incorporating I/O
执行 IO 的时候,调度别的进程。
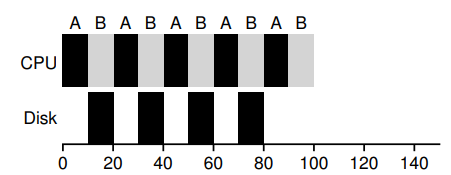
Chapter8 Sheduling: The Multi-Level Feedback Queue(MLFQ)
MLFQ 算法会维护一系列Queues, 拥有不同的优先级。
- Rule1: Priority(A)>Priority(B), 运行进程 A.
- Rule2: Priority(A)=Priority(B), A 和 B 以 RR(Round Robin)规则运行.
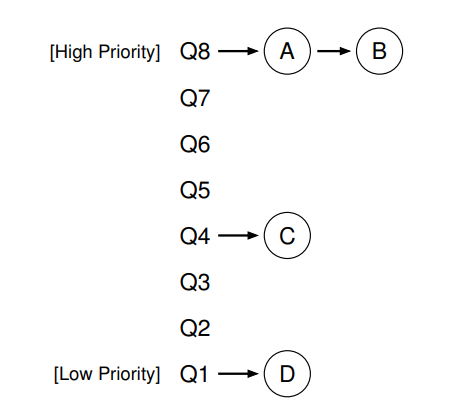
- Rule3: 一个进程刚到来时,属于最高优先级。
- Rule4a: 如果进程用完了自己的 allotment, 会降低一个优先级。
- Rule4b: 如果进程在用完 allotment 前放弃了 CPU(比如进行 IO 操作),会停留在当前优先级,allotment 重置。(Figure 8.3b)
Examples:

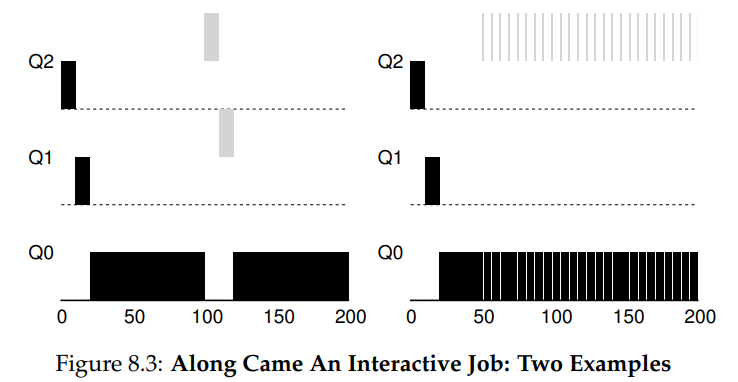
目前为止 MLFQ 存在的问题
- Starvation 饥饿问题。如果有太多短时的进程,运行时间长的进程会拿不到 CPU。
- Game the scheduler 欺骗调度器。一个恶意的用户程序,可以在每次即将用完 allotment 时,进行一次 IO 操作,这样又可以停留在最高优先级了。
Priority boost
为了解决饥饿问题,增加第五条规则:
- Rule5: 经过固定时间 S, 把所有进程的优先级都调到最高。
这个时间 S 也称作 voo-doo constants,比如把 voo-doo constants 设置为 100ms:
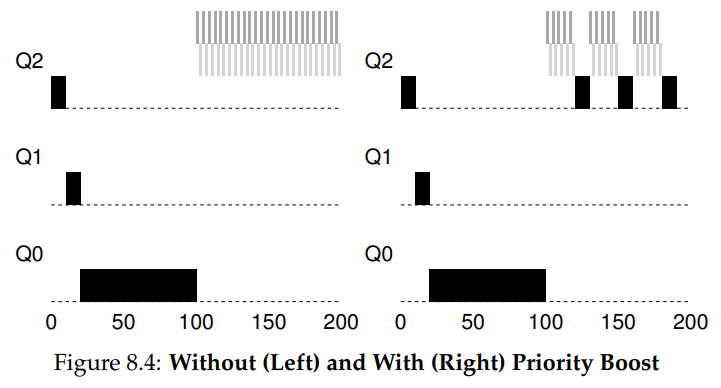
Better Accounting
为了解决 Game the scheduler 的问题,修改 Rule 4a 和 4b,不再是计算单次使用 CPU 的 alloment,而是:
- Rule4: 当一个进程在某一优先级的总时间用完后,降低一个优先级。
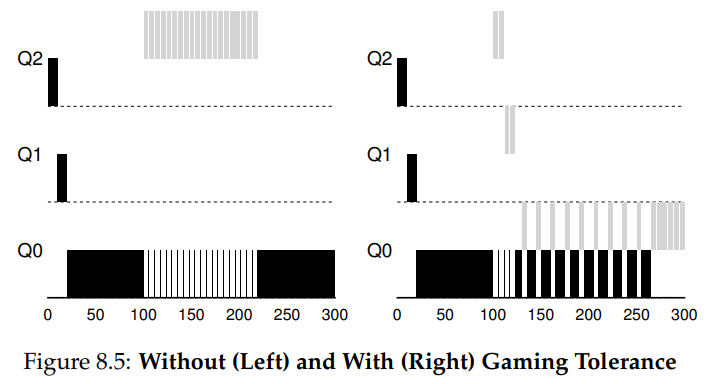
Tuning MLFQ
一些参数是可以调整的,Queue 的数量,time slice,allotment,priority boost time。
一种可以优化的做法是越高优先级的队列,time slice 越短。
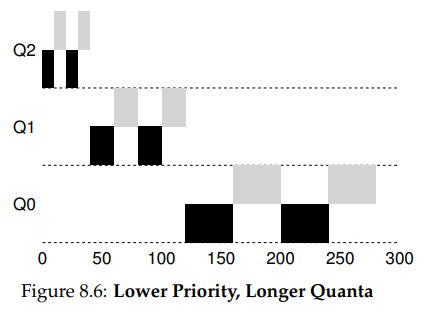
Chapter9 Scheduling: Proportional Share
比例份额调度(proportinal-share),也称公平份额调度(fair-share)。
9.2 Lottery Scheduling
每个进程分配一个 Ticket,生成一个位于 0~sum_tickets 随机数 winner,如下图如果 winner 位于 0~99,进程 A 执行; 100~149,进程 B 执行; 150~400,进程 C 执行。

实现代码:
// counter: used to track if we’ve found the winner yet
int counter = 0;
// winner: call some random number generator to
// get a value >= 0 and <= (totaltickets - 1)
int winner = getrandom(0, totaltickets);
// current: use this to walk through the list of jobs
node_t *current = head;
while (current) {
counter = counter + current->tickets;
if (counter > winner)
break; // found the winner
current = current->next;
}
// ’current’ is the winner: schedule it...
Lottery scheduling 存在的问题有,如果 job length 很短的话会存在不公平的现象。还有一个是如何分配 tickets。参考 9.4 和 9.5 章节。
9.6 Stride Scheduling
仍然给 A,B,C 分别分配 tickets100,50,250,在 Stride scheduling 中需要一个总目标数,比如 10000,用 1000 计算 A,B,C 的步长,10000/100=100, 10000/50=200, 10000/250=40。
Basic idea: at any given time, pick the process to run that has the lowest pass value so far; when you run a process, increment its pass counter by its stride.
curr = remove_min(queue); // pick client with min pass
schedule(curr); // run for quantum
curr->pass += curr->stride; // update pass using stride
insert(queue, curr); // return curr to queue
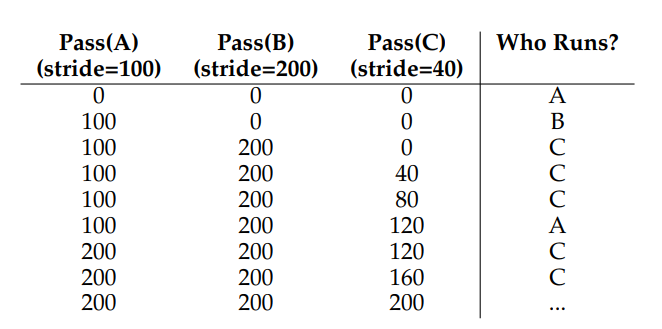
Pass Value 相同时随机选择进程 Run。
Stride Scheduling 存在的问题有,如果新来一个进程,那么这个进程的 pass value 会是 0,会持续运行该进程,占据 CPU 一段时间。
9.7 The Linux Completely Fair Scheduler(CFS)
所有竞争的进程公平地分配 CPU 使用。
每个进程运行会累计virtual runtime, CPU 会选择 vruntime 最小的进程来 run。
存在的问题有,如果 CPU 切换太快,context switch 对系统的性能损耗太大。如果 CPU 切换太慢,进程间的公平性又会降低。
CFS 算法为了解决上述问题,提供了一些控制参数:
- sched_latency: context switch 之前进程应该跑多久,典型值为 48ms。如果此时有 n 个进程一起在 running,sched_latency=48/n。如下图所示,一开始有 4 个进程一起跑,sched_latency 比较短,后面只有两个进程在跑,sched_latency 变长。

如果有太多进程一起在 running,那么 sched_latency 就会被分的很小,为了解决这个问题,提出了第二个控制参数:
- min_granularity: 典型值 6ms。进程最短的运行时间,不能再被分割。
Weighting(Niceness)
Unix 系统可以通过修改nice值来调整进程权重,可选值为-20~+19。
根据权重再调整进程的 time_slice。
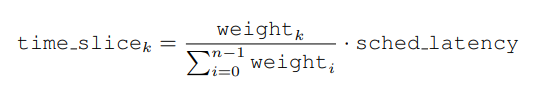
n 为总进程数,k 为当前进程。weight:

vruntime 计算也需要调整:
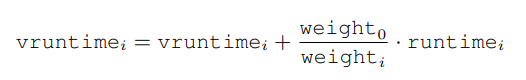
Using Red-Black Trees
进程用链表查找太慢了,CFS 使用红黑树来管理正在 running 的进程。